TDD
General Info
Test-driven development (TDD), is a new age evolutionary approach to development which emphasizes test-first development. Here you write a test before you write just enough production code to fulfill that test and then go on to refactor the code. The primary goal of TDD is specification and not validation (Martin, Newkirk, and Kess 2003). In other words, TDD is one way to think through your requirements or design before your write your functional code (implying that TDD is both an important agile requirements and agile design technique). Another view is that TDD is a programming technique. As Ron Jeffries likes to say, the goal of TDD is to write clean code that works.
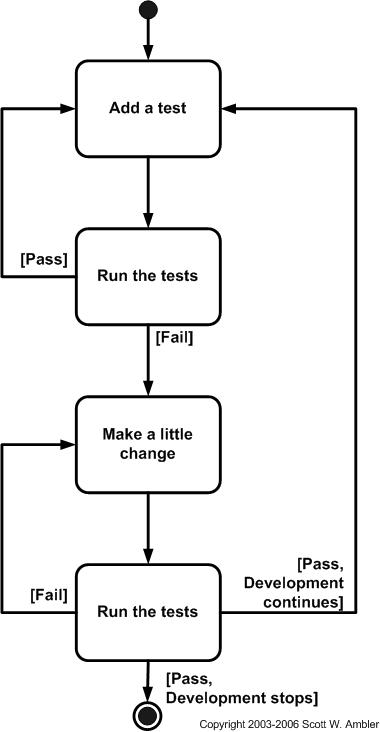
The first step is to quickly add a test, basically just enough test for your code to fail. Next you run your tests, often the complete test suite although for sake of speed you may decide to run only a subset, to ensure that the new test does in fact fail. You then update your functional code to make it pass the new tests. The fourth step is to run your tests again. If they fail you need to update your functional code and retest until the tests pass.
Why should developers care about automated unit tests?
- Keeps you out of the (time hungry) debugger!
- Reduces bugs in new features and in existing features
- Reduces the cost of change
- Improves design
- Encourages refactoring
- Builds a safety net to defend against other programmers
- Is fun
- Forces you to slow down and think
- Speeds up development by eliminating waste
- Reduces fear
How does TDD take development to the next level?
- Improves productivity by
- minimizing time spent debugging
- reduces the need for manual (monkey) checking by developers and tester
- helping developers to maintain focus
- reduce wastage: hand overs
- Improves communication
- Creating living, up-to-date specification
- Communicate design decisions
- Learning: listen to your code
- Baby steps: slow down and think
- Improves confidence
- Testable code by design + safety net
- Loosely-coupled design
- Refactoring
In summary, the importance of TDD cannot be overemphasized. TDD means less bugs, higher quality software, and a razor focus, but it can slow development down and the test suites can be tedious to manage and maintain. All in all, it is a recommended approach as the Pros far outweighs the Cons.
TDD should lead to better design
The process of learning effective TDD is the process of learning how to build more modular applications. TDD tends to have a simplifying effect on code, not a complicating effect. If you find that your code gets harder to read or maintain when you make it more testable, or you have to bloat your code with dependency injection boilerplate, you’re doing TDD wrong.
- You can write decoupled code without dependency injection, and
- Maximizing code coverage brings diminishing returns — the closer you get to 100% coverage, the more you have to complicate your application code to get even closer, which can subvert the important goal of reducing bugs in your application.
More complex code is often accompanied by more cluttered code. You want to produce uncluttered code for the same reasons you want to keep your house tidy:
- More clutter leads to more convenient places for bugs to hide, which leads to more bugs, and
- It’s easier to find what you’re looking for when there’s less clutter to get lost in.
Code Smells
“A code smell is a surface indication that usually corresponds to a deeper > problem in the system.” ~ Martin Fowler
What is a Mock
A mock is a test double that stands in for real implementation code during the unit testing process. A mock is capable of producing assertions about how it was manipulated by the test subject during the test run. If your test double produces assertions, it’s a mock in the specific sense of the word.
The term “mock” is also used more generally to refer to the use of any kind of test double.
What is a unit test?
Unit tests test individual units (modules, functions, classes) in isolation from the rest of the program.
Contrast unit tests with integration tests, which test integrations between two or more units, and functional tests, which test the application from the point of view of the user, including complete user interaction workflows from simulated UI manipulation, to data layer updates, and back to the user output (e.g., the on-screen representation of the app).
Functional tests are a subset of integration tests, because they test all of the units of an application, integrated in the context of the running application.
In general, units are tested using only the public interface of the unit (aka “public API” or “surface area”). This is referred to as black box testing. Black box testing leads to less brittle tests, because the implementation details of a unit tend to change more over time than the public API of the unit. If you use white box testing, where tests are aware of implementation details, any change to the implementation details could break the test, even if the public API continues to function as expected. In other words, white-box testing leads to wasted rework.
Test Coverage
Code coverage refers to the amount of code covered by test cases. Coverage reports can be created by instrumenting the code and recording which lines were exercised during a test run. In general, we try to produce a high level of coverage, but code coverage starts to deliver diminishing returns as it gets closer to 100%.
What most people don’t realize is that there are two kinds of coverage:
- Code coverage: how much of the code is exercised, and
- Case coverage: how many of the use-cases are covered by the test suites
Because use-cases may involve the environment, multiple units, users, and networking conditions, it is impossible to cover all required use-cases with a test suite that only contains unit tests. Unit tests by definition test units in isolation, not in integration, meaning that a test suite containing only unit tests will always have close to 0% case coverage for integration and functionaluse-case scenarios
100% code coverage does not guarantee 100% case coverage.
Developers targeting 100% code coverage are chasing the wrong metric.
Tight Coupling
The need to mock in order to achieve unit isolation for the purpose of unit tests is caused by coupling between units. Tight coupling makes code more rigid and brittle: more likely to break when changes are required. In general, less coupling is desirable for its own sake because it makes code easier to extend and maintain. The fact that it also makes testing easier by eliminating the need for mocks is just icing on the cake.
From this we can deduce that if we’re mocking something, there may be an opportunity to make our code more flexible by reducing the coupling between units. Once that’s done, you won’t need the mocks anymore.
Coupling is the degree to which a unit of code (module, function, class, etc…) depends upon other units of code. Tight coupling, or a high degree of coupling, refers to how likely a unit is to break when changes are made to its dependencies. In other words, the tighter the coupling, the harder it is to maintain or extend the application. Loose coupling reduces the complexity of fixing bugs and adapting the application to new use-cases.
Coupling takes different forms:
- Subclass coupling: Subclasses are dependent on the implementation and entire hierarchy of the parent class: the tightest form of coupling available in OO design.
- Control dependencies: Code that controls its dependencies by telling them what to do, e.g., passing method names, etc… If the control API of the dependency changes, the dependent code will break.
- Mutable state dependencies: Code that shares mutable state with other code, e.g., can change properties on a shared object. If relative timing of mutations change, it could break dependent code. If timing is nondeterministic, it may be impossible to achieve program correctness without a complete overhaul of all dependent units: e.g., there may be an irreparable tangle of race conditions. Fixing one bug could cause others to appear in other dependent units.
- State shape dependencies: Code that shares data structures with other code, and only uses a subset of the structure. If the shape of the shared structure changes, it could break the dependent code.
- Event/message coupling: Code that communicates with other units via message passing, events, etc…
Causes of Tight Coupling
- Mutation vs immutability
- Side-Effects vs purity/isolated side-effects
- Responsibility overload vs Do One Thing (DOT)
- Procedural instructions vs describing structure
- Class Inheritance vs composition
Imperative and object-oriented code is more susceptible to tight coupling than functional code. That doesn’t mean that programming in a functional style makes your code immune to tight coupling, but functional code uses pure functions as the elemental unit of composition, and pure functions are less vulnerable to tight coupling by nature.
How to Pure Functions Reduce Coupling?
Pure functions:
- Given the same input, always return the same output, and
- Produce no side-effects
They reduce coupling by:
- Immutability: Pure functions don’t mutate existing values. They return new ones, instead.
- No side effects: The only observable effect of a pure function is its return value, so there’s no chance for it to interfere with the operation of other functions that may be observing external state such as the screen, the DOM, the console, standard out, the network, or the disk.
- Do one thing: Pure functions do one thing: Map some input to some corresponding output, avoiding the responsibility overload that tends to plague object and class-based code.
- Structure, not instructions: Pure functions can be safely memoized, meaning that, if the system had infinite memory, any pure function could be replaced with a lookup table that uses the function’s input as an index to retrieve a corresponding value from the table. In other words, pure functions describe structural relationships between data, not instructions for the computer to follow, so two different sets of conflicting instructions running at the same time can’t step on each other’s toes and cause problems.
How to Remove Coupling
To remove coupling, we first need a better understanding of where coupling dependencies come from. Here are the main sources, roughly in order of how tight the coupling is:
Tight coupling:
- Class inheritance (coupling is multiplied by each layer of inheritance and each descendant class)
- Global variables
- Other mutable global state (browser DOM, shared storage, network, etc…)
- Module imports with side-effects
- Implicit dependencies from compositions, e.g., const enhancedWidgetFactory = compose(eventEmitter, widgetFactory, enhancements); where widgetFactory depends on eventEmitter
- Dependency injection containers
- Dependency injection parameters
- Control parameters (an outside unit is controlling the subject unit by telling it what to do)
- Mutable parameters
Loose coupling:
- Module imports without side-effects (in black box testing, not all imports need isolating)
- Message passing/pubsub
- Immutable parameters (can still cause shared dependencies on state shape)
Ironically, most of the sources of coupling are mechanisms originally designed to reduce coupling. That makes sense, because in order to recompose our smaller problem solutions into a complete application, they need to integrate and communicate somehow. There are good ways, and bad ways. The sources that cause tight coupling should be avoided whenever it’s practical to do so. The loose coupling options are generally desirable in a healthy application.
You might be confused that I classified dependency injection containers and dependency injection parameters in the “tight coupling” group, when so many books and blog post categorize them as “loose coupling”. Coupling is not binary. It’s a gradient scale. That means that any grouping is going to be somewhat subjective and arbitrary.
Can the unit be tested without mocking dependencies? If it can’t, it’s tightly coupled to the mocked dependencies.
The more dependencies your unit has, the more likely it is that there may be problematic coupling. Now that we understand how coupling happens, what can we do about it?
- Use pure functions as the atomic unit of composition, as opposed to classes, imperative procedures, or mutating functions
- Isolate side-effects from the rest of your program logic. That means don’t mix logic with I/O (including network I/O, rendering UI, logging, etc…)
- Remove dependent logic from imperative compositions so that they can become declarative compositions which don’t need their own unit tests. If there’s no logic, there’s nothing meaningful to unit test
That means that the code you use to set up network requests and request handlers won’t need unit tests. Use integration tests for those, instead.
That bears repeating:
Don’t unit test I/O. I/O is for integrations. Use integration tests, instead.
It’s perfectly OK to mock and fake for integration tests.
Use pure functions
Using pure functions takes a little practice, and without that practice, it’s not always clear how to write a pure function to do what you want to do. Pure functions can’t directly mutate global variables, the arguments passed into them, the network, the disk, or the screen. All they can do is return a value.
If you’re passed an array or an object, and you want to return a changed version of that object, you can’t just make the changes to the object and return it. You have to create a new copy of the object with the required changes. You can do that with the array accessor methods (e.g, concat, filter, map, reduce, slice), Object.assign(), using a new empty object as the target, or the array or object spread syntax.
For example:
// Not pure
const signInUser = user => user.isSignedIn = true;
const foo = {
name: 'Foo',
isSignedIn: false
};
// Foo was mutated
console.log(
signInUser(foo), // true
foo // { name: "Foo", isSignedIn: true }
);
vs…
// Pure
const signInUser = user => ({...user, isSignedIn: true });
const foo = {
name: 'Foo',
isSignedIn: false
};
// Foo was not mutated
console.log(
signInUser(foo), // { name: "Foo", isSignedIn: true }
foo // { name: "Foo", isSignedIn: false }
);
You can use that trick to make React components render faster if you have a complex state tree that you may not need to traverse in depth with each render pass. Inherit from PureComponent and it implements shouldComponentUpdate() with a shallow prop and state comparison. When it detects identity equality, it knows that nothing has changed in that part of the state tree and it can move on without a deep state traversal.
Pure functions can also be memoized, meaning that you don’t have to build the whole object again if you’ve seen the same inputs before. You can trade computation complexity for memory and store pre-calculated values in a lookup table. For computationally expensive processes which don’t require unbounded memory, this may be a great optimization strategy.
Another property of pure functions is that, because they have no side-effects, it’s safe to distribute complex computations over large clusters of processors, using a divide-and-conquer strategy. This tactic is often employed to process images, videos, or audio frames using massively parallel GPUs originally designed for graphics, but now commonly used for lots of other purposes, like scientific computing.
In other words, mutation isn’t always faster, and it is often orders of magnitude slower because it takes a micro-optimization at the expense of macro-optimizations.
Isolate side-effects from the rest of your program logic
There are several strategies that can help you isolate side-effects from the rest of your program logic. Here are some of them:
- Use pub/sub to decouple I/O from views and program logic. Rather than directly triggering side-effects in UI views or program logic, emit an event or action object describing an event or intent.
- Isolate logic from I/O e.g., compose functions which return promises using
asyncPipe(). - Use objects that represent future computations rather than directly triggering computation with I/O, e.g.,
call()fromredux-sagadoesn't actually call a function. Instead, it returns an object with a reference to a function and its arguments, and the saga middleware calls it for you. That makescall()and all the functions that use it pure functions, which are easy to unit test with no mocking required.
Use Pub/Sub
Pub/sub is short for the publish/subscribe pattern. In the publish/subscribe pattern, units don’t directly call each other. Instead, they publish messages that other units (subscribers) can listen to. Publishers don’t know what (if any) units will subscribe, and subscribers don’t know what (if any) publishers will publish.
Pub/sub is baked into the Document Object Model (DOM). Any component in your application can listen to events dispatched from DOM elements, such as mouse movements, clicks, scroll events, keystrokes, and so on. Back when everyone built web apps with jQuery, it was common to jQuery custom events to turn the DOM into a pub/sub event bus to decouple view rendering concerns from state logic.
Pub/sub is also baked into Redux. In Redux, you create a global model for application state (called the store). Instead of directly manipulating models, views and I/O handlers dispatch action objects to the store. An action object has a special key, called type which various reducers can listen for and respond to. Additionally, Redux supports middleware, which can also listen for and respond to specific action types. This way, your views don't need to know anything about how your application state is handled, and the state logic doesn't need to know anything about the views.
It also makes it trivial to patch into the dispatcher via middleware and trigger cross-cutting concerns, such as action logging/analytics, syncing state with storage or the server, and patching in realtime communication features with servers and network peers.
Isolate logic from I/O
Sometimes you can use monad compositions (like promises) to eliminate dependent logic from your compositions. For example, the following function contains logic that you can’t unit test without mocking all of the async functions:
async function uploadFiles({user, folder, files}) {
const dbUser = await readUser(user);
const folderInfo = await getFolderInfo(folder);
if (await haveWriteAccess({dbUser, folderInfo})) {
return uploadToFolder({dbUser, folderInfo, files });
} else {
throw new Error("No write access to that folder");
}
}
Remember: Logic and I/O are separate concerns. Logic is thinking. Effects are actions. Think before you act!
Sources
Most of this info was copied from this Medium Article by Eric Elliot